Data Cleansing in SQL: Traditional vs Generative AI-based Techniques
Traditional data cleansing in SQL focuses on addressing data quality issues such as duplicates, missing values, and inconsistencies. For example, an SQL query can identify and remove duplicates to avoid errors in downstream systems, like business intelligence dashboards. With the rise of generative AI, it is natural to ask whether traditional data cleansing is now redundant. Can we simply provide structured data, warts and all, to a generative AI-based system?
This article explains the role of data cleansing in SQL and the emergence of generative AI in data analysis. It shows an example of interacting with structured data using generative AI to illustrate the model's sensitivity to input data errors, prompt phrasing, and system instructions. The motivation for these examples is to highlight the importance of metadata because generative AI is based on large language models (LLMs). Descriptive metadata is a key ingredient in helping LLMs understand the language of structured data.
Summary of key data cleansing in SQL concepts
Here is a quick summary of the concepts covered in this article.
Traditional data cleansing
Traditional data cleansing in SQL focuses on the data by removing duplicates, identifying missing values or outliers, or performing type conversion and value standardization.
Shown below are some tables from a consumer goods company. There are three main tables: Orders, Products, and Customers. The tables have various data issues, which are easy enough to spot with such a small data sample.
Orders table
Product table
Customers table
Traditional data cleansing in SQL helps avoid error propagation to downstream systems. Looking at the example above, we see duplicates in the Orders table: row 3 is a duplicate of row 1, and row 5 is a duplicate of row 2. Note how the duplicates inflate the quantities, which will overstate revenue in the sales report. Here is a simple query to dedupe the Orders table:
DELETE FROM orders
WHERE rowid NOT IN (
SELECT MIN(rowid)
FROM orders
GROUP BY order_id, customer_id, product_id, order_date, quantity
);The Orders table will now look like the following after deduping -
Other examples of traditional data cleansing are:
- Missing value imputation: Missing values can be predicted based on trends in the existing data.
- Outlier/anomaly analysis: Outliers might be data points of interest or incorrectly recorded data. Calculating the interquartile range can identify potential outliers.
- Type conversion: Sometimes numbers are stored as strings; to perform calculations, these strings need to be represented as numbers.
- Standardization: An example of this is ensuring that all financial transactions are recorded in a consistent currency.
{{banner-large-1="/banners"}}
Limitations of traditional data cleansing techniques
The main limitation of traditional data cleansing techniques is that they tend to be manual processes in which an issue is identified, and an SQL query is developed to address it. This is because structured data is often displayed via dashboards, and issues are spotted within visualizations. For example, a graph with the date on one axis does not display correctly, and the issue is identified as dates being recorded with different conventions: MM/DD/YY, DD-MM-YYYY, or YYYY-MM-DD. A data cleansing script is then developed to tackle this problem, and it might correct the underlying data or be applied on the fly to produce the visualization.
Another example of where traditional data cleansing can struggle is fuzzy matching. Knowing all the possible patterns or typos in a string in advance is impossible. This is a significant limitation of REGEXP and LIKE because they rely on us providing a static word to match.
Given the rise of generative AI, is traditional data cleansing even necessary? Can generative-AI-based systems analyze raw structured data?
Using generative AI to analyze structured data
Let’s look at using the raw example data with generative AI. The tables were turned into three CSV files, and these were uploaded to Google Gemini using the following Python code:
# import libraries
import google.generativeai as genai
import glob
import os
# set API key
genai.configure(api_key=os.environ["API_KEY"])
# create a model
foundation_model = "gemini-1.5-flash"
model = genai.GenerativeModel(foundation_model)
# set system instructions
model = genai.GenerativeModel(
foundation_model,
system_instruction="""
You have been provided CSVs of Orders, Products, and Customers from a company that sells consumer goods.
Your task is to help analyze these CSVs.
"""
)
# upload CSVs to gemini
dirpath = <path location of CSVs>
uploaded_csvs = [""]
for name in glob.glob(dirpath+r'\*.csv'):
uploaded_csv = genai.upload_file(name)
uploaded_csvs.append(uploaded_csv)Follow this link to obtain an API key for Google Gemini. A Python quick start guide is also available here, but the structure of the Python code is as follows:
- Import the SDK and configure your API key.
- Create a model based on using gemini-1.5-flash.
- Provide system instructions to the model to explain how we want the model to behave.
- Upload the three CSVs so that the model can access them.
The next stage was to create a Python script to ask questions about the CSVs. The following template was used for this:
promptIn = "How many orders are there?"
uploaded_csvs[0] = promptIn
temp = 0.8
response = model.generate_content(
uploaded_csvs,
generation_config=genai.GenerationConfig(
temperature=temp,
candidate_count=1
)
)
print(response.text)The output from the “how many orders are there?” prompt was:
“There are 6 unique orders in the provided data. Note that order IDs 1001 and 1002 appear twice, but they are still counted as a single order each.”
Looking at the orders table, we see duplicates in the Orders table: Row 3 is a duplicate of row 1, and row 5 is a duplicate of row 2. Unfortunately, even though the model recognized that order IDs 1001 and 1002 appear twice, it still reported the wrong number of unique orders.
If we ask “how many unique orders are there?” the response is:
“There are 5 unique orders. Even though order IDs 1001 and 1002 appear twice in the `orders` data, they represent the same order. The unique order IDs are 1001, 1002, 1003, 1004, and 1005.”
If we say “count the number of orders," the response is:
“There are 6 unique orders in the provided data. Note that orders 1001 and 1002 appear twice, but are counted only once because the data shows duplicate entries for the same order.”
If we ask “what is the total number of orders?” the response is:
“There appear to be 5 unique orders in the provided data, based on the `order_id` column. However, there are 6 rows in the `order` table because orders 1001 and 1002 are duplicated.”
If we ask “how many rows are in the orders table? Explain your calculation of the number of rows” the response is:
“The orders table has 7 rows. I determined this by counting the number of rows in the provided data for the `order_id`, `customer_id`, `product_id`, `order_date`, `quantity`, and `amount` columns. Each row represents a unique order.”
The example above highlights some challenges of analyzing structured data with generative AI. The model's response can be wrong or misleading and is sensitive to the input prompt's phrasing. We can improve the robustness of the response by updating the system instructions with the sentence, "Be careful when analyzing the different CSVs to check for duplicate rows. These should not be counted, and you should explain when rows have been ignored."
model = genai.GenerativeModel(
foundation_model,
system_instruction="""
You have been provided CSVs of Orders, Products, and Customers from a company that sells fast-moving consumer goods.
Your task is to help analyze these CSVs.
Be careful when analyzing the different CSVs to check for duplicate rows. These should not be counted, and you should explain when rows have been ignored.
"""
)Now, when asked “how many orders are there?” the output is::
“There are 5 unique orders.
“The provided order CSV contains duplicate rows (order IDs 1001 and 1002 are duplicated). These duplicates have been ignored in the count of unique orders. There are 2 duplicate rows for order_id 1001 and 2 duplicate rows for order_id 1002. These were excluded from the count.”
We have improved the model's response by providing further information in the system instruction. In the examples above, the response would not have had errors if a duplicate-free Orders table had been input into the model, so traditional data cleansing is still relevant in generative AI-based systems. It also shows that for generative AI to provide better responses to questions about the underlying data, the AI system needs to be provided with metadata that:
- Describes the data sources
- Describes columns
- Captures key business dates like financial year-end
- Captures key business jargon, for example, definitions of customer churn or large customers
Since AI-based systems are based on LLMs, providing these metadata as sentence-based descriptions helps provide context and enables deeper insights.
Generative-AI-based data cleansing
The example above demonstrated some limitations of generative AI-based data analysis. Careful prompting is needed to ensure that the model has appropriate context. We needed to make the model aware that the data might have issues. This also demonstrates the potential of generative AI for data cleansing. With the right prompts, generative AI can move beyond traditional rule-based cleansing and empower non-technical uses.
Semantic fuzzy matching
GenAI-based systems surpass traditional data cleansing in SQL because they eliminate the need for the REGEXP and LIKE operators, which require users to define static string patterns to match on. Trained on large language datasets, GenAI is capable of dynamically understanding typos and contextual variations in strings that SQL-based methods lack.
Context-awareness
GenAI-based systems integrate location-based metadata with the unit, helping the system detect which unit system is predominantly used in a region. In other words, these models have the contextual awareness that, for example, US-based products are generally measured in inches whereas EU-based products are measured in centimeters. GenAI-based systems go a step further by flagging inconsistencies in the database, such as having mixed-up unit information (the US location has some products listed in inches and some in centimeters).
Standardization
GenAI-based systems can help format inconsistencies in data. For example, they can identify and flag records with two different date formats: “MM/DD/YYYY” and “DD/MM/YYYY.” They can also help maintain uniform units and notations throughout (e.g., “USD” vs “$”).
GenAI’s real-time integration capabilities can be particularly effective in currency standardization because it is possible to fetch the latest currency exchange rates through external APIs and perform currency conversions instantly. GenAI systems can also standardize categorical data fields and ensure uniformity in spelling while considering regional relevance (e.g., color vs. colour, meters vs. metres). These capabilities come from two core functionalities of GenAI: semantic text normalization and data profiling.
Getting deeper insights with generative AI
In traditional data analysis, insights are often developed by annotating and discussing business intelligence dashboards. The image below shows an example of a business intelligence dashboard for an insurance company. The insights gained from viewing this dashboard will depend on the individual's expertise in the insurance domain, business understanding, and role within the organization.
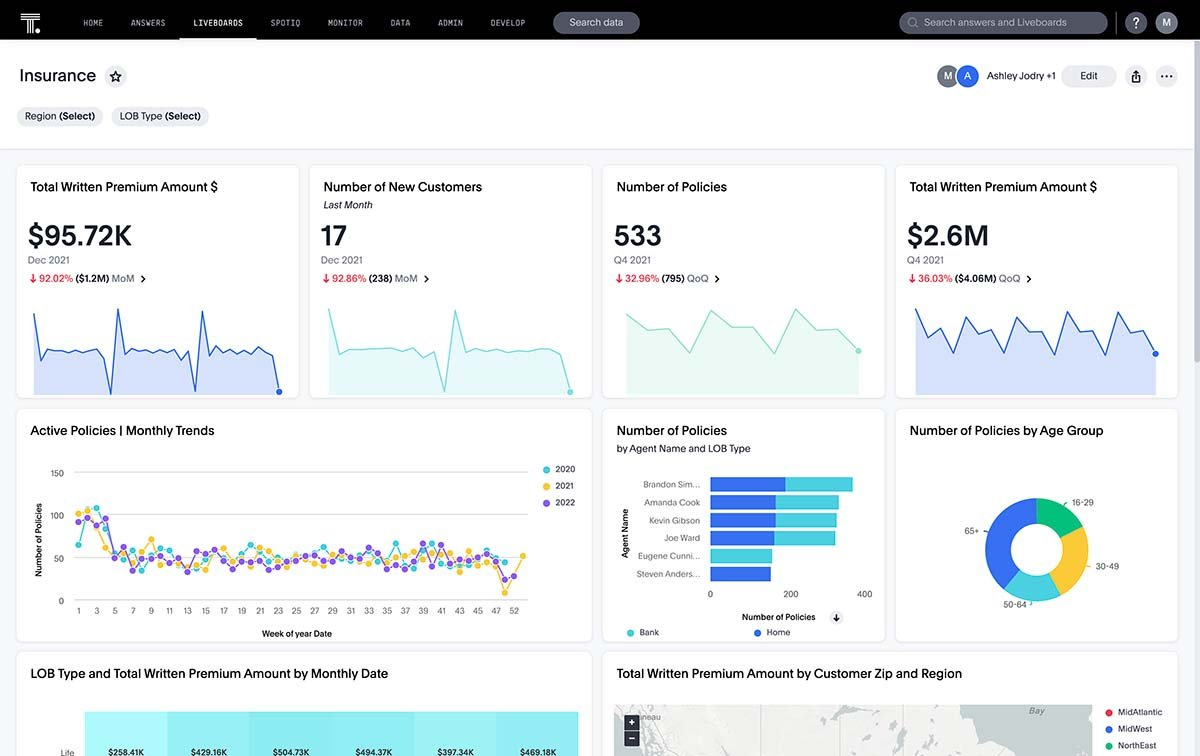
Similarly, further information about the tables themselves could be provided to the generative AI model or further definitions could be provided, such as “large customers are defined as those ordering more than 100 items.” This metadata enables the AI-based system to understand questions like “how many large customer orders were there in April?” The following sections explain how metadata is incorporated into AI-based systems.
{{banner-small-1="/banners"}}
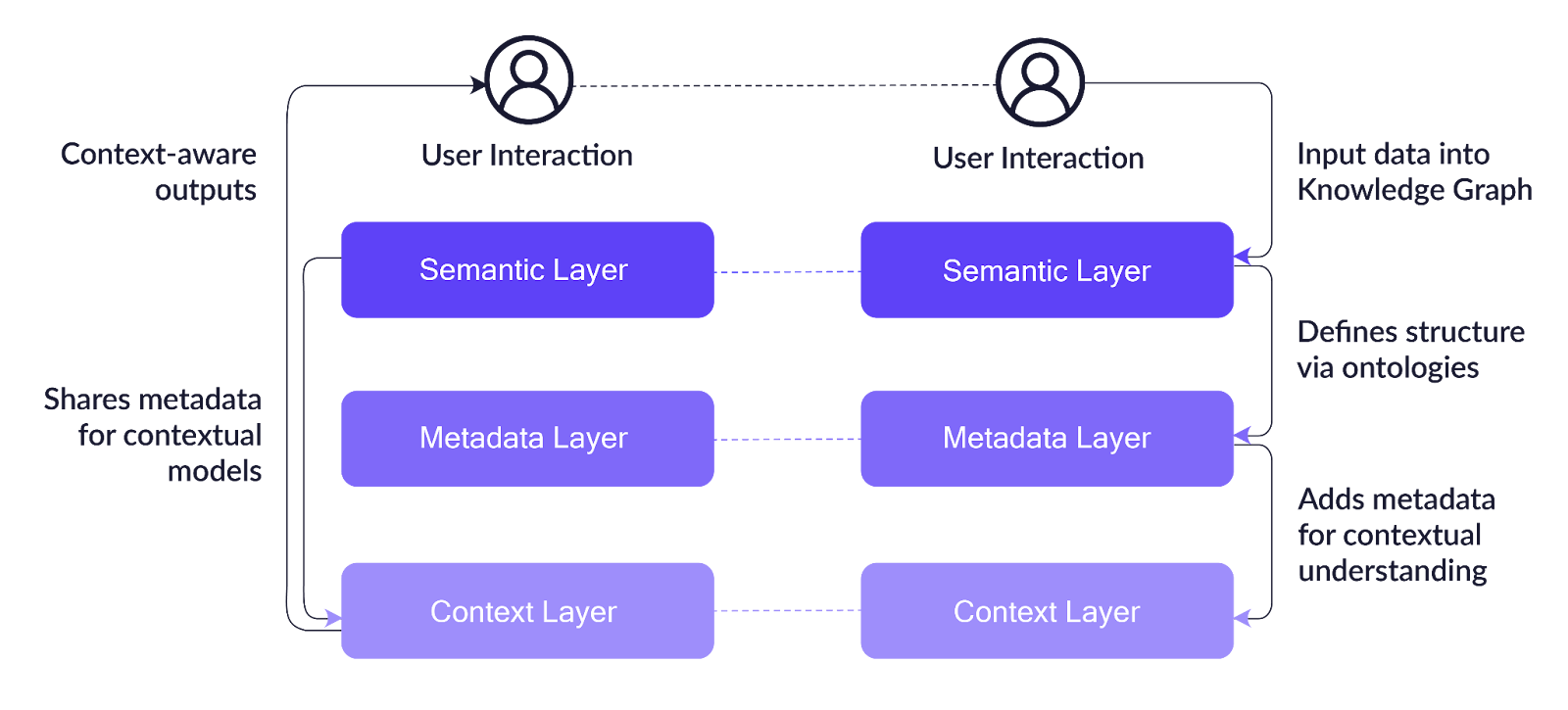
Capturing metadata with knowledge architecture entities
A visual illustration of a generative AI knowledge architecture is shown below. The diagram illustrates how data input by a user flows through the three core layers of an AI-based system. The semantic layer processes the input data from the user and creates a knowledge graph with the entities and their associated attributes. The metadata layer determines the structure and relationships among the various entities. The semantic layer then shares the knowledge graph and metadata with the context layer. It is the context layer that adds real-time awareness by considering factors that influence how the input data should be interpreted (i.e., context-sensitive inputs).
Business rules dictate how a company’s data and schemas should be set up and organized. Data pipelines need to adapt to any changes to pricing models and reporting standards. For instance, let’s assume that a company’s initial reporting policy was to recognize all shipped orders as revenue, but later on, it was decided that only invoiced orders should be recognized as revenue. This would mean that all the data pipelines that populate current and past orders should be adjusted so that only invoiced orders are considered for revenue. The data schemas of the tables that populate the reports should also be adjusted for the change.
The impact of such changes on GenAI models is huge, especially when the overlaying AI-powered platform has a static context layer. They would need to undergo fine-tuning, recalibration, and retraining to ensure that the shipping date is no longer considered for the revenue calculation.
Importance of the semantic layer in data cleansing
The semantic layer plays a vital role in creating a unified data landscape. But what makes it possible? This is where knowledge graph integration and automated schema mapping come into play. Knowledge graph integration combines data from various sources such as relational databases, NoSQL databases, and data files and establishes relationships among people, events, and geographies in the gathered data. Knowledge graphs also help with disambiguation by helping the GenAI model differentiate similar entities, such as “Apple” (the company) vs. “apple” (the fruit).
Automated schema mapping refers to the process of automatically aligning varying field names and formats of data points, especially when they come from multiple data sources. Let’s say a company creates a master sales report to consolidate data from various product lines. Each product line has its own database, and the field representing the sales amount is labeled differently in each database. For instance, let’s assume the following:
- The beverage product line’s sales are labeled “beverage_sales_total.”
- The snacks product line has its sales labeled “snacks_sales_amt.”
- The personal care product line has its sales labeled “personal_care_revenue.”
Without automated schema mapping, the company’s data engineers must standardize the field names to aggregate them. With automated schema mapping in place, GenAI models can automatically recognize that these three all represent sales revenue across different product lines.
{{banner-small-1="/banners"}}
Importance of the context layer in data cleansing
The real-time awareness in the context layer stems from one of its crucial functionalities: named entity recognition (NER). NER is a natural language processing technique that involves identifying and categorizing key information such as people, locations and events present in data. In GenAI-based systems, NER is used to identify important entities from a user’s natural language query so that the query can be constructed accurately by the text-to-SQL application.
NER performs three primary functions:
- Entity tagging: labeling key entities
- Entity standardization: standardizing entities to a universal format
- Noise removal: removing irrelevant words and phrases
Let’s look at these using an example. Let’s say that a stakeholder is interested in the total sales of their company ABCD in the Northeast region. They type the following natural language query in the text-to-SQL application: “Hey, could you please provide me with the total sales figures for ABCD, specifically within the Northeast region of the United States, for the last quarter, which I believe ended on September 30th, and also include any relevant sales data for the same period in the previous year for comparison purposes? Oh, and by the way, I'd love to get some insights on our top-performing products in that region as well. Thanks!”
The manner in which NER is performed by the context layer is shown in the table below.
The outcome is the simplified natural language query: “Provide total sales for ABCD in Northeast (U.S.) for Q3 2024 vs Q3 2023.” This is then fed to the GenAI model, which generates an optimal SQL query that results in accurate financials being reported to the stakeholder.
Metadata as a bridge between the semantic and context layers
The metadata layer integrates the semantic and context layer through two core functionalities: data annotation and metadata enrichment. Data annotation refers to the process of labeling data with the appropriate tags to improve retrieval of data. An example of data annotation would be to label customer reviews as positive, negative, and neutral. Metadata enrichment adds additional context to the data to make it more meaningful. For example, the metadata layer can use the session logs in a Customer data table to get the geolocation.
Let’s use an example to see how the metadata layer communicates with both the semantic and context layers. Imagine that the following is a text-to-SQL query asked by a stakeholder: “Highlight sales that exceeded our expectations for our beverage product line last quarter in the Northwest region.”
The semantic layer uses named entity recognition to tag the important entities in the natural language input. In this case, it tags “sales that exceeded our expectations,” “last quarter,” “Northwest,” and “beverage product line.”
The metadata layer maps each entity to the corresponding column in the database (data annotation). For example:
- “NW Region” is mapped to the sales_region column in the Sales table.
- “Product” is mapped to the product_category column in the Product Lookup table.
- “Quarter” is mapped to the appropriate hierarchical dimension of time_period in the database ensuring the right year, month and dates are chosen. E.g. As of January 2025, the last quarter was October 1, 2024, to December 31, 2024.
The relationship between the tagged entities is identified using metadata enrichment within the metadata layer. Relationships are defined between the database columns “product_category,” “sales_region,” and “time_period.”
The context layer adds real-time contextual awareness, including additional rules enriched from domain-specific knowledge, such as defining thresholds for outliers (e.g., sales > +3 standard deviations from mean). This is needed to answer the question of “sales that exceeded expectations.” It then further narrows the focus to data from the last quarter.
{{banner-small-1="/banners"}}
Last thoughts
Traditional SQL-based data cleansing is important for ensuring data quality and accuracy, and this remains true with the advent of generative AI-based systems. However, the success of these AI-powered systems also heavily relies on the quality and completeness of the metadata that describes the structured data. Generative AI can analyze structured data, and traditional data cleansing is relevant to avoiding errors in generative AI systems like text-to-SQL.
The article emphasized the importance of a well-defined knowledge architecture, including a semantic layer for entity recognition and schema mapping, a metadata layer for data annotation and enrichment, and a context layer for real-time awareness and domain-specific knowledge. By effectively integrating these components, organizations can unlock the full potential of generative AI in their data analysis workflows, leading to more accurate, insightful, and actionable results.
AI-powered platforms with a dynamic context layer, such as WisdomAI, can adapt to redefined metrics and realign the reports and key insights based on the new metric calculation (in this case, revenue calculation based on the invoiced date). Unlike a static context layer, a dynamic context layer can remap metric definitions at runtime, reducing the need for manual recalibrations or retraining the underlying ML model.